

Improving AI Accuracy by 10% Not with Better Models, But Better Context
Friday is an AI-powered analytics platform that lets data analysts query their data in plain language. The AI was good until it hit a database it had never seen before. This is how we fixed that.
Role
UX Designer
Industry
B2B, SaaS, Agentic AI
Customer
Material Depot & PwC
This Project Comes under NDA, for that it covers the surface of the project.
An AI That Lets You Talk to Your Data, In Plain English
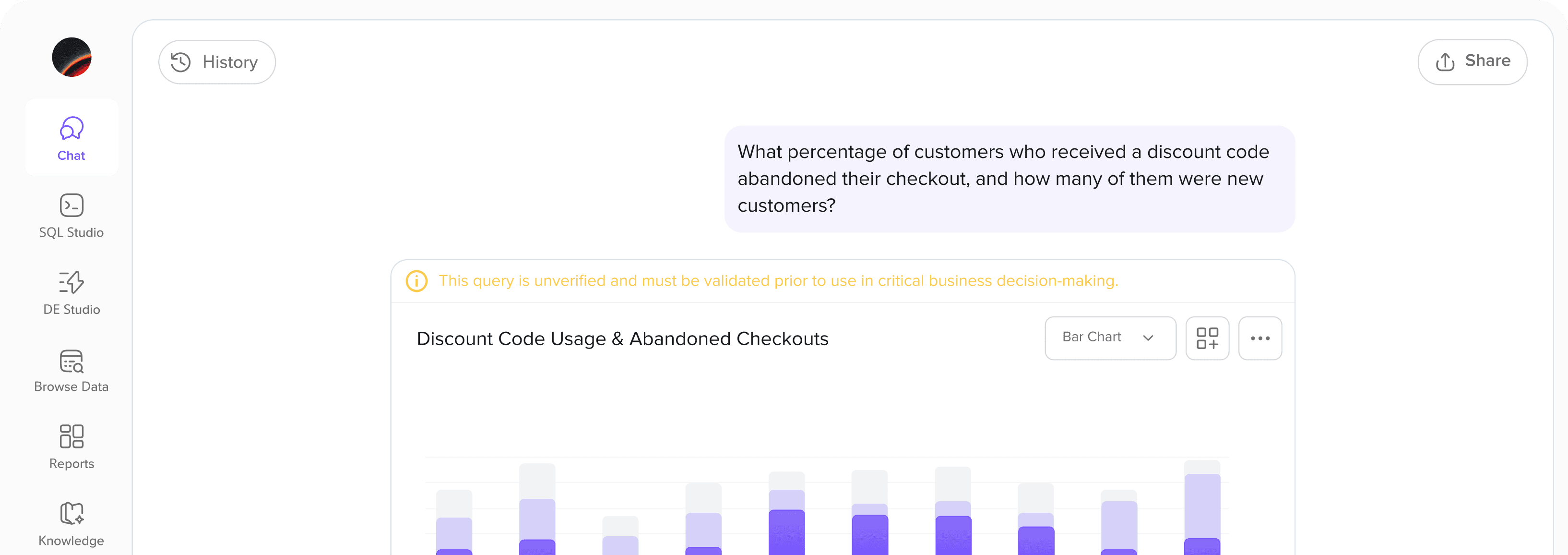
Friday is an AI-powered analytics platform built for data analysts. Instead of writing SQL, analysts ask questions in natural language, 'What were last quarter's top-performing regions?' and Friday translates that into queries, retrieves the results, and surfaces insights. It's an agentic system: the AI interprets intent, maps terms to schema, generates SQL, and returns answers. Each step in that chain is a potential point of failure. When Friday worked, it felt like having a senior analyst on call. When it didn't, it hallucinated numbers that looked plausible enough to be trusted.


The AI Excelled on Familiar Data. Everything Else Was a Guess.
Friday performed well on its training database, the one it knew intimately. But the moment analysts pointed it at an unfamiliar dataset, accuracy degraded. Not catastrophically. Subtly. The answers looked right. The numbers were plausible. The formatting was clean. But the underlying queries were wrong.
That's the most dangerous kind of failure in an analytics tool: confident incorrectness. An analyst who sees a hallucinated revenue figure formatted in a clean table is more likely to trust it than question it.
The breakdown came from four places:
Ambiguous natural language: 'sales' could mean orders, revenue, or bookings depending on who was asking.
Schema inconsistencies: the same concept lived in columns named revenue, rev_usd, and net_revenue across different databases.
No shared business glossary: each department used terms differently, and the AI had no way to know which definition applied.
Weak reference points: when the AI lacked context, it hallucinated rather than admitted uncertainty.
I Didn't Fix the Model. I Fixed What the Model Could See.
I led design on this project as part of a team of five, 2 UX designers, a project lead, 3 AI engineers and 2 Developers. My scope covered the full design arc, from early problem framing through to usability testing and dev handoff.
Instead of fine-tuning a model, we designed a knowledge base with the AI and the Human can see and understand.
My contribution spanned the full system:
Mapping the AI decision flow from prompt to output
Designing the metadata and glossary experience
Structuring the human-in-the-loop review system
Creating flows for both technical analysts and non-technical business users
Introducing 20 new components aligned to the existing design system
Three Questions Before a Single Screen Was Designed
Before touching Figma, I forced three questions that shaped everything:
1. What does 'accuracy' actually mean here?
Not a percentage. Not a benchmark. Accuracy, for an analyst, means, I understand where this answer came from. I can verify it if I need to. And I trust it enough to act on it.
2. Where exactly does the AI fail?
The failure wasn't random. It was systematic, concentrated at the intent-to-schema mapping step. When the AI didn't know what a term meant in the context of a specific database, it guessed. And it guessed confidently.
3. What would make a user trust the AI more over time?
Not a disclaimer. Not an error message. A system where the AI learns from verified human answers, builds a vocabulary of approved terms, and becomes more accurate the more it's used.
These three questions eliminated several solution directions before we explored any of them.
Working directly with the AI team revealed that any AI operated in two distinct layers, an internal prompting layer that guided how the model responded, and a context layer that carried the surrounding intelligence, metadata, schema descriptions, glossary definitions, and historical correction signals. That distinction was the turning point. The model wasn't the only issue. In many cases, Friday was making the wrong decision because it didn't have enough context to make the right one.
We also studied seven competing platforms, HEX, Julius AI, ThoughtSpot, Fire AI, Atlan, ChatGPT, and Gemini. What we found was consistent, the industry was strong on generation. It was much weaker on semantic grounding. Most tools could produce an answer. Very few could help the AI understand what the question actually meant in the context of a specific business.
That gap became Friday's opportunity.
We Tried Three Approaches and None of Them Alone was Enough
Accuracy wasn't a single design problem. It was three overlapping problems, each with its own solution and only when combined did they actually work. Here's how we found that out.
Iteration 1: Saved Queries & Verification Loop
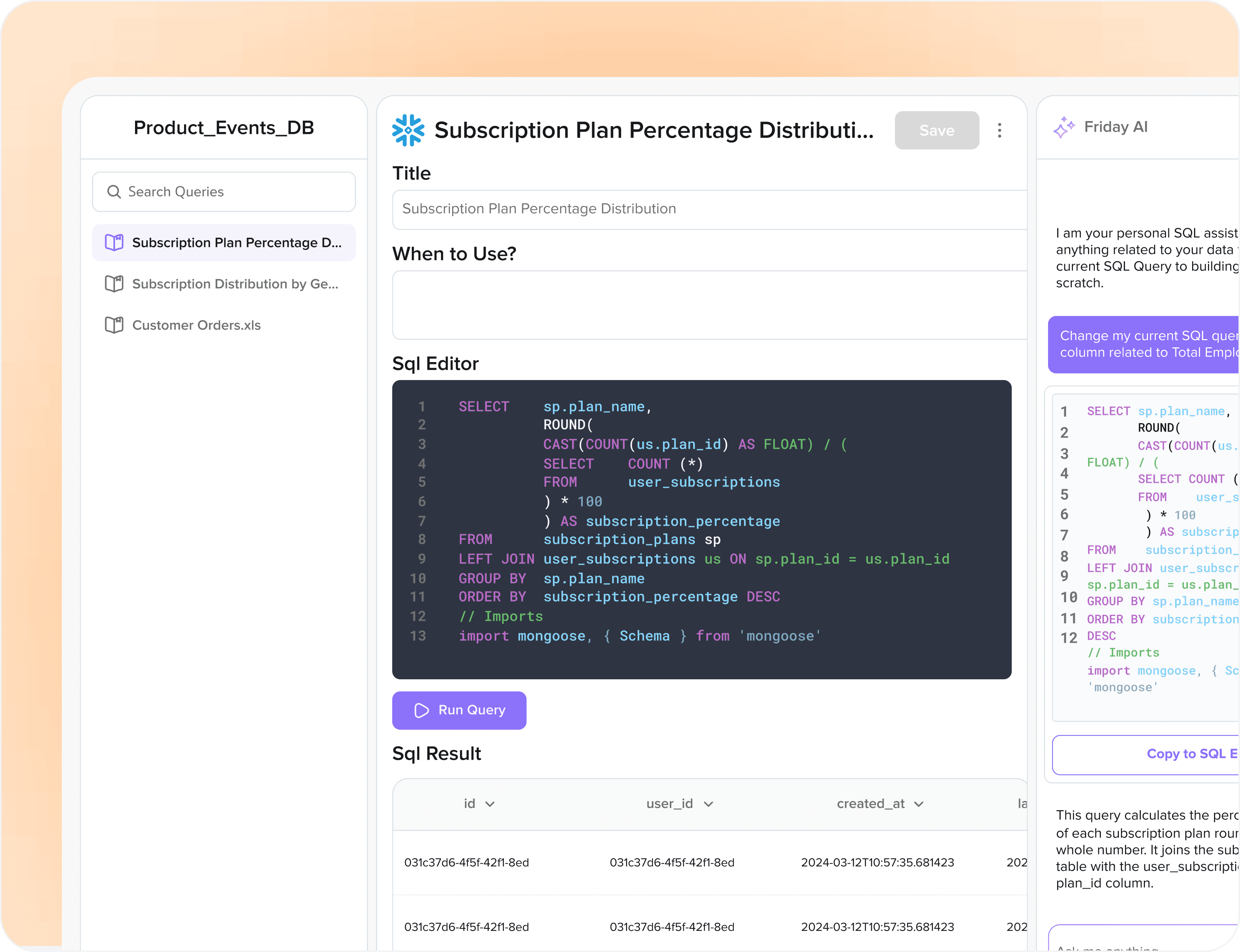
Our first direction was a feedback mechanism: any AI output could be sent for analyst verification, then saved as a 'verified query' for future use. If the same question came up again, Friday would reuse the trusted query rather than regenerating it.
What worked: response time dropped by 20% on repeated or similar queries. Token consumption dropped by 100% on exact repeats, which halved the cost per query. Because analytical questions are often repeated across teams, the verified query library became a compounding efficiency asset.
What didn't: the moment an analyst asked about an unfamiliar database, the verified query library was useless. Saved queries are a library of known answers. They're not a map of unknown territory.
Conclusion: powerful optimisation for known queries. Zero help for the core problem.
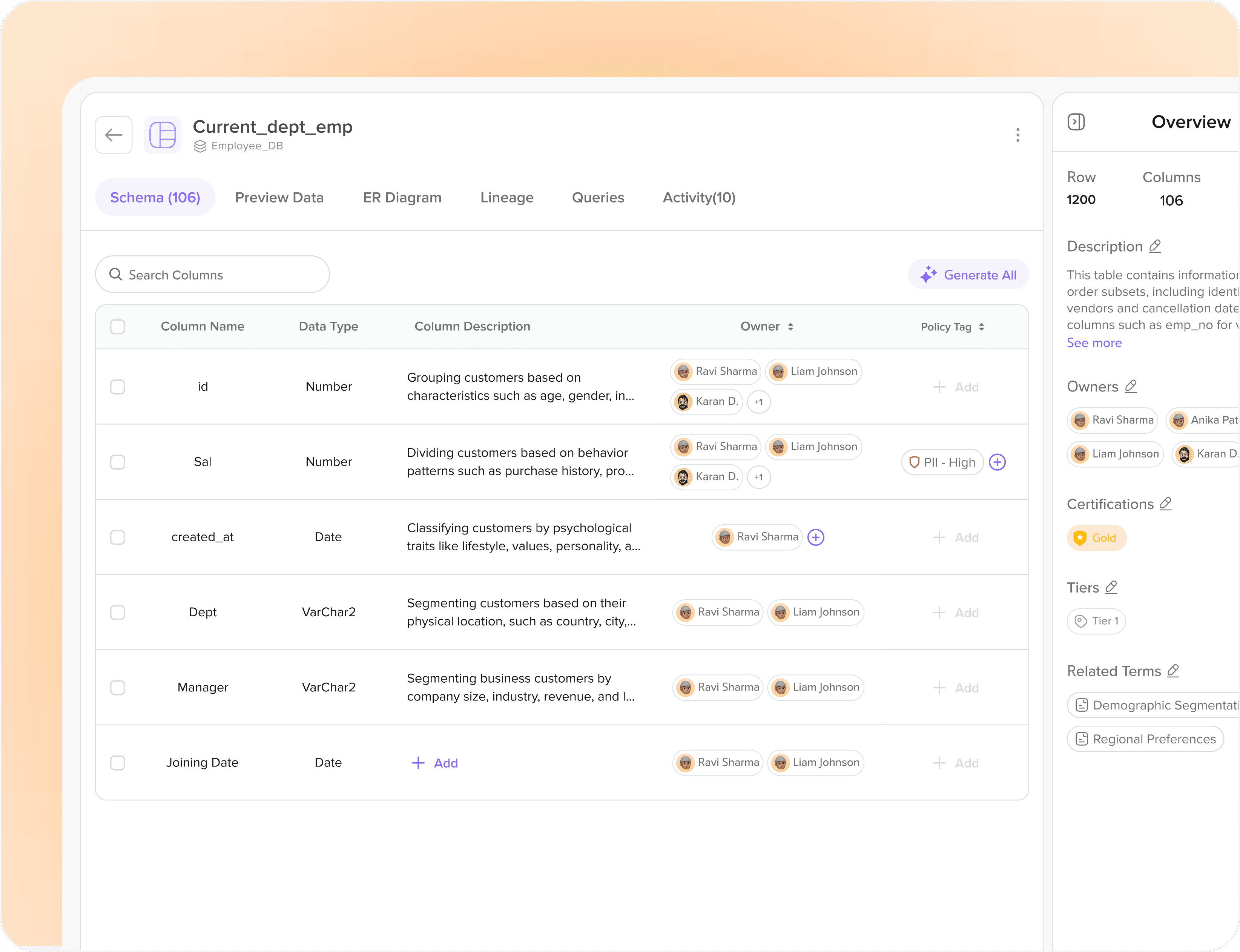
Iteration 2: Metadata
Next, we designed metadata for every table and column, giving the AI explicit, human-authored descriptions of what each data point meant. Column named rev_usd? The metadata said: 'Net revenue in US dollars, post-refund, pre-tax, for the EMEA region.'
What worked: metadata dramatically improved accuracy on both known and unknown databases. The AI now had a map.
What didn't: writing metadata manually was unsustainable at scale. We explored AI-generated metadata. Initially, it underperformed human-authored descriptions, but with iteration, it reached a usable quality level, making it a viable way to bootstrap context for new datasets.
Conclusion: solved the schema problem. Didn't solve the business vocabulary problem.
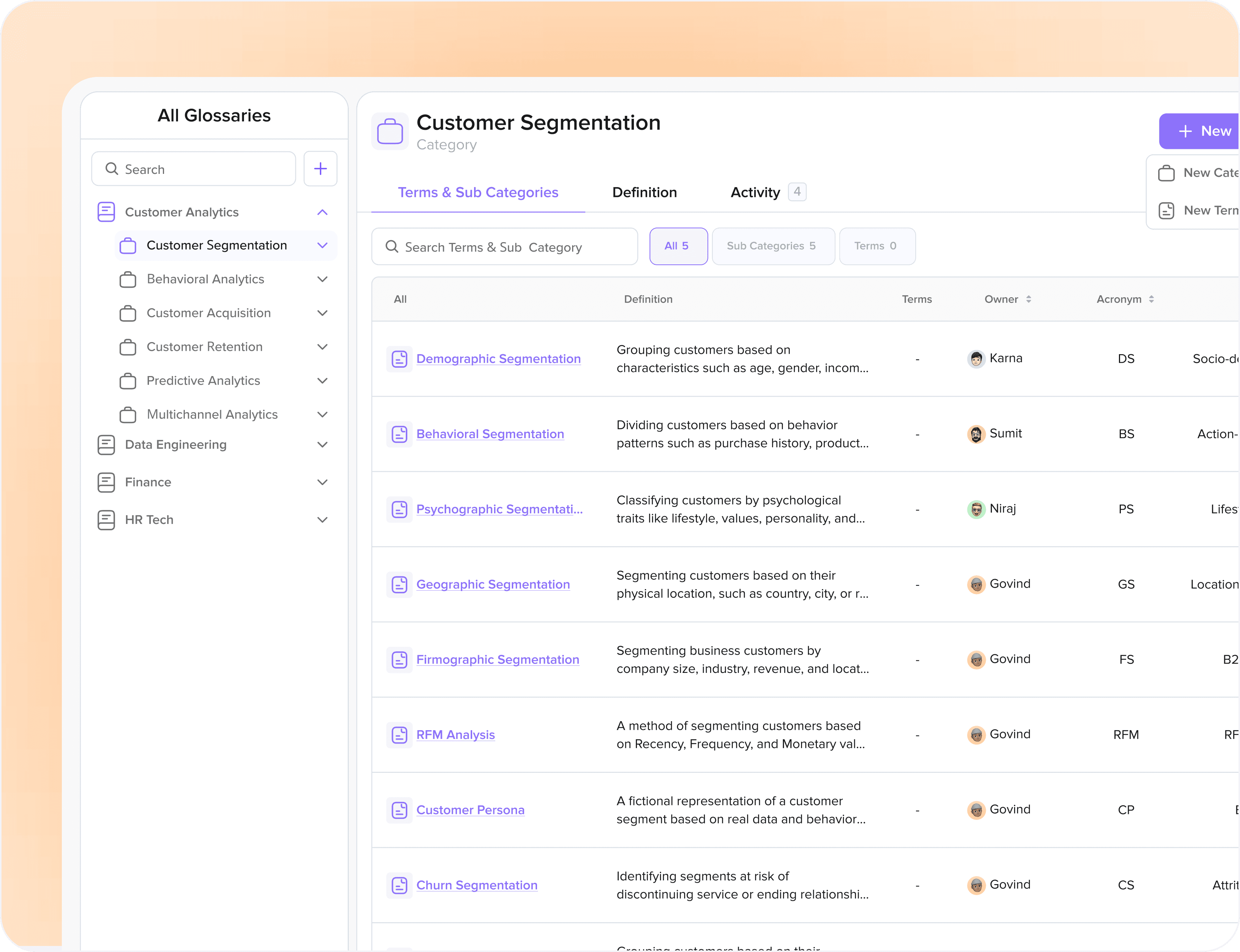
Iteration 3: Business Glossary
The final piece was a structured knowledge base of company-approved business terms. Each entry included a definition, synonyms and acronyms, related terms, and the specific columns or tables it mapped to.
Why 'revenue' needed a glossary entry, in one department, it meant gross revenue. In another, net. In a third, it excluded a specific product line. The AI had no way to know which definition applied until the glossary told it.
What worked: rich semantic grounding. The AI now knew not just what a column contained, but what the business meant when they used a term.
Conclusion: solved the vocabulary problem. Didn't replace metadata.
Each solution had a ceiling. Saved queries couldn't handle unfamiliar databases. Metadata couldn't capture business intent. The glossary couldn't describe column relationships. But together, as a unified Knowledge Base, they covered each other's gaps. We didn't pick the best solution. We combined all three and staged the rollout.
Not One Solution. A System Where All Three Work Together.
The Knowledge Base is a three-layer context system that surrounds the AI with everything it needs to reason accurately about any database it encounters.
Layer 1: Saved Queries, a verified answer library. When an analyst confirms an AI output is correct, it's saved. The next time a similar question is asked, Friday draws on that verified answer rather than regenerating from scratch. Faster. Cheaper. Trusted.
Layer 2: Metadata, a structured description of every table and column in the connected database. Human-authored content where precision is critical. AI-generated where scale demands it. The AI now knows not just that a column called rev_usd exists, it knows exactly what it contains and how it should be used.
Layer 3: Business Glossary, a living dictionary of company-specific terms, definitions, synonyms, and the columns they map to. When an analyst asks about 'revenue,' the glossary tells Friday which definition applies, before the query is even generated.
Together, the AI has a verified answer history, a map of the data, and a vocabulary of the business. Accuracy doesn't depend on the model getting lucky. It depends on the context being rich enough that luck isn't needed.
The design challenge was to make this three-layer system feel like one coherent product, not three bolted-on features. Every flow had to close the loop clearly. Technical analysts needed control and transparency. Non-technical users needed simplicity and confidence. The same underlying system had to serve both.
To keep implementation efficient, we aligned with the existing design system and introduced 20 new components. Engineering overhead stayed low. Visual consistency stayed intact.
Tested Against 100+ Real Queries Across Client Database
After the solution was designed and implemented, we tested it against real client databases, not synthetic data, not internal test sets. Real queries from real analysts working on real business problems.
We benchmarked the system across more than 100 user queries and evaluated how well the improved context handling affected result quality. The benchmark covered queries across familiar and unfamiliar databases, simple and compound questions, and both technical and non-technical phrasings.
The result: an 8–10% improvement in accuracy.
Importantly, that improvement came not from changing the model, but from improving the context around the model. Friday became better not because it became smarter in a general sense, but because it became more grounded in the specific business environment it was operating in.
That distinction matters. It means the accuracy improvement compounds: every new glossary entry, every verified query, every metadata description makes the system incrementally more accurate. The Knowledge Base doesn't just fix today's wrong answers, it makes tomorrow's answers less likely to be wrong.
Show slow-moving SKU clusters where stock rotation is below target fill-rate threshold for the last 2 quarters.
Detect abnormal inventory shrinkage patterns in bulk construction material lots by warehouse and shift.
Compare OTIF performance across vendors supplying structural steel over the last 6 months.
Which suppliers have breached agreed lead time SLA windows more than 3 times in the current procurement cycle?
Analyse vendor ASN accuracy deviation against actual GRN timestamps.
What is the correlation between supplier fill rate deterioration and downstream order fulfillment delays?
50%
60%
70%
80%
90%
10%
20%
30%
40%
100%
0%
Base Model
Without Context
With Context
Saved Query
Meta Data
Business Glossary
~10% More Accuracy, Trusted by Fortune 500 Clients
The project delivered impact at two levels.
Product impact:
1. 8–10% improvement in AI accuracy across real client queries
2. Reduced hallucinated analytics outputs
3. Increased trust in generated responses, analysts started using Friday for questions they'd previously run manually
Business impact:
1. The improved workflow helped expand Friday to two additional clients
2. Both clients came from Fortune 500, validating the solution at enterprise scale
3. The product proved that context design can directly influence adoption and reliability
The 10% accuracy improvement understates what actually changed. The real shift was that Friday became a tool analysts relied on, not one they double-checked. That transition, from skeptical user to confident user, is the outcome that matters for a B2B analytics product.
The system also improves over time by design. Each verified query makes the saved library richer. Each glossary entry makes the semantic grounding stronger. Accuracy isn't a fixed number, it's a compounding curve.
Being in New Domain was not an disadvantage
Friday changed how I think about AI product design. It made one thing very clear: in AI systems, context is not a supporting detail. It is part of the product itself.
I came into this project knowing very little about how LLMs work under the hood. That turned out to be an asset. The engineers had strong instincts about model improvement, fine-tuning, prompt engineering, and context window management. Those instincts were right, technically. But they were also in tunnel vision. The assumption was that accuracy was a model problem. I didn't know enough to share that assumption, so I questioned it.
That question, 'what if the model is fine, and the context is the problem?', led directly to the Knowledge Base design. Fresh eyes aren't always naive. Sometimes they ask the question that people, too close to the problem, have stopped asking.
What I'd carry forward:
1. Clean output does not guarantee correctness
2. Trust is built through structure, not just polish
3. Semantic clarity matters just as much as interface clarity
4. The best AI products help users believe the right thing, not just see something impressive
There's More to This Story. Let's Talk.
Due to confidentiality, certain product screens, client data, and internal workflows aren't publicly shareable here. But they exist, and I'd be glad to walk you through them. I can take you through the full metadata management flow, the human-in-the-loop validation UI, the governance design for Big Four clients, and the components we didn't ship in V1.
If this project resonates with the kind of work you're hiring for, let's have that conversation.